SpringMVC 常见误区
十年之前,基于 Struts 的 MVC 是很普遍的。但,就近几年来看,我发现 SpringMVC 越来越受欢迎了。当然,这并不奇怪,因为它可以和 SpringMVC 更无缝的衔接和更好的灵活性和扩展性。
从我开始用 Spring 到现在,我发现有些人在配置 Spring 框架的时候经常有些小错误。这比人们在用 Struts 框架的时候更多。我猜这可能就是灵活性和可用性的代价吧。而且,Spring 的文档中很多例子,但却没有足够的解释。为了弥补这个缺陷,这篇文章中我会详细阐述三个经常碰到的错误。
在 ServletContext 配置文件中配置 Bean
我们都知道,Spring 通过 ContextLoaderListener 来加载 Spring 的上下文。然而,当我们声明 DispatcherServlet 的时候,我们需要创建一个用 “${servlet.name}-context.xml” 命名的 ServletContext 配置文件。想过这是为什么吗?
应用上下文的树形结构
不是所有的开发者都知道 Spring 的应用上下文有树形结构。让我们看下这个方法:
org.springframework.context.ApplicationContext.getParent()
它告诉我们 Spring 的上下文是有父结点的。那么,这个父结点是什么呢?
如果你下载下它的源码并作个快速检索,你就会发现 SpringApplicationContext 把它的父结点作为它的扩展。如果你也对此感兴趣的话,就让我们看看它在 BeanFactoryUtils.beansOfTypeIncludingAncestors() 方法中的用途:
1
2
3
4
5
6
7
8
9
10
if (lbf instanceof HierarchicalBeanFactory) {
HierarchicalBeanFactory hbf = (HierarchicalBeanFactory) lbf;
if (hbf.getParentBeanFactory() instanceof ListableBeanFactory) {
Map parentResult = beansOfTypeIncludingAncestors((ListableBeanFactory) hbf.getParentBeanFactory(), type);
...
}
}
return result;
}
如果你看完这个方法,你就会发现 SpringApplicationContext 会先在自身上下文中查找对应的 Bean,然后再查找父结点上下文。通过这种策略,SpringApplicationContext 通过广度优先搜索算法查找目标 Bean。
ContextLoaderListener
这个每个开发者都应该了解的类。它可以帮助从预定义的配置文件中加载 SpringApplicationContext。因为它继承自 ServletContextListener,所以 SpringApplicationContext 会在 WEB 应用启动后立即开始加载。这在加载有 @PostContruct 注解的 Bean 或者批量任务的时候无疑是有好处的。
相对比的,在 Servlet 上下文的定义文件中的 Bean 只会在 Servlet 初始化的时候才开始组装。然后什么时候 Servlet 初始化呢?这是不确定的,在最坏的情况下,你可能要等到第一个用户发起这个 Servlet 对应的请求时才会加载 Spring 的上下文。
了解了这些信息,明白应该在哪声明 Bean 了吗?我觉得加载配置文件最合适的方式就是通过 ContextLoaderListener。这地方有一个需要注意的就是 ApplicationContext 会被存储在 Servlet 的属性中,对应的主键是 org.springframework.web.context.WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE。然后,DispatcherServlet 会从取出这个上下文并把它当作父结点。
1
2
3
4
5
6
protected WebApplicationContext initWebApplicationContext() {
WebApplicationContext rootContext = WebApplicationContextUtils.getWebApplicationContext(getServletContext());
...
}
基于这种特性,非常推荐使用空的 ServletApplicationContext 配置文件,并把所有的 Bean 配置在它的父结点上。这可以避免重复的 Bean 创建,也可以保证批量任务的立即执行。
理论上,在 ServletApplicationContext 中定义 Bean 还可以保证其唯一性和仅对 Servlet 可见。但是,在我使用 Spring 的 8 年时间中,这种特性也就在定义 WebService 的接口上有作用。
在 ContextLoaderListener 前面声明 Log4jConfigListener
有一个很小的 Bug 但你要不注意的话也可能造成大麻烦。Log4jConfigListener 是比使用 -Dlog4j.configuration 参数更好的方案,因为这样我们可以在不修改服务进程的情况下控制 Log4j 加载。
很明显的,这应该是你在 web.xml 中声明的第一个 Listener。否则,你在声明日志系统上作的所有配置可能都是无效的。
管理不善导致的重复 Bean
在 Spring 的早期过程中,人们花在编写 xml 配置文件上的时间比写代码更多。每一个新的 Bean,都需要手动的声明和组装,很清晰,很整洁,也很痛苦。后面的版本中 Spring Framework 在易用性上做了很大的努力。到了今天,开发者可能只需要声明事务控制器,数据源,引用文件源,WebService 终端结点等,然后把其余的都用自动扫描和自动注入。
我很喜欢这种方式,但更大的权利往往也伴随着更大的责任,否则,事情可能很快就会变糟。组件扫描和在 xml 中声明 Bean 是完全独立的。所以,如果一个 Bean 既通过自动扫描声明了,也通过配置声明了,那么它在容器中就会有两个实例。当然,这种错误也只有新手会犯。
当我们需要在最终产品里集成一些嵌入式组件时情况就有点复杂了。这时候我们需要一些策略来避免重复的 Bean 声明。
Spring 组件
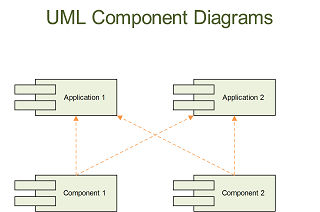
上面的图中展示了我们在工作中是经常遇到的一种情况。很多时候,一个系统是由很多个组件组成的,而且经常的,一个组件也服务于很多产品。每个应用和组件都有它们自己的 Bean。在这种情况下,怎么才能更好的避免重复的 Bean 声明呢?
我的建议如下:
- 确保每个组件都有一个自己专用的包名称。这样更利于自动扫描。
- 不要让团队通过组件内部声明(注解或者配置文件)的方式开发组件。这应该是把组件集成到最终产品的开发人员的责任,因为他们才能知道是不是存在重复 Bean。
- 如果在组件内部有配置文件,把它放在包路径下,不要放在根下。更好的做法是给它一个特殊的名字。例如
src/main/resources/spring-core/spring-core-context.xml比src/main/resource/application-context.xml就好很多。设想一下,如果我们在集成的时候发现几个组件中有着完全同名的配置文件,而且路径也一样,该怎么处理,然后你就明白我们前面做法的好处了。 - 如果你已经在配置文件中声明 Bean 了就不要再给它添加任何组件声明(@Component, @Service or @Repository)。
- 把数据源、配置文件源之类的特殊配置拆分到不同的配置文件以便于重用。
- 不要在普遍性的包上做组件扫描。例如,对比扫描
org.springframework,扫描几个子包org.springframework.core,org.springframework.context,org.springframework.ui无疑更容易管理。